An AI strategy for startups is a framework for making 6 key decisions: build vs. integrate, model selection, RAG architecture, agentic patterns, data strategy, and compliance. Here's how to build one.
Every startup founder has seen the same demo. An AI feature that looks magical in a Loom video. GPT-wrapper magic that makes investors nod.
Then the engineering team tries to ship it. Latency hits 4 seconds. Costs spike to $2 per query. Hallucinations show up in production. The "AI-powered" feature gets quietly killed three months later.
This isn't an AI problem. It's a strategy problem.
After building AI-native products like Sociail (an AI workplace platform with 2,300+ beta users) and SuppGenie (a research engine processing 220M+ scientific papers), we've developed a clear framework for how startups should think about AI — not as a feature checkbox, but as a technical architecture decision that compounds or collapses over time.
Here's what actually works.
Why Do Most Startup AI Projects Fail After the Demo?
There's a pattern we see in nearly every startup that comes to us after their AI initiative stalls:
Week 1–2: Engineer builds a prototype using the OpenAI API. It works. Everyone's excited.
Month 2: The prototype goes to staging. Edge cases multiply. Prompt engineering becomes a full-time job. Costs are 10x what anyone budgeted.
Month 4: The feature either ships half-broken or gets shelved. The team is demoralized. The board asks "what happened to our AI strategy?"
The gap between demo and production isn't about better prompts. It's about six decisions that most startups never make deliberately.
What Are the Key Decisions in a Startup AI Strategy?
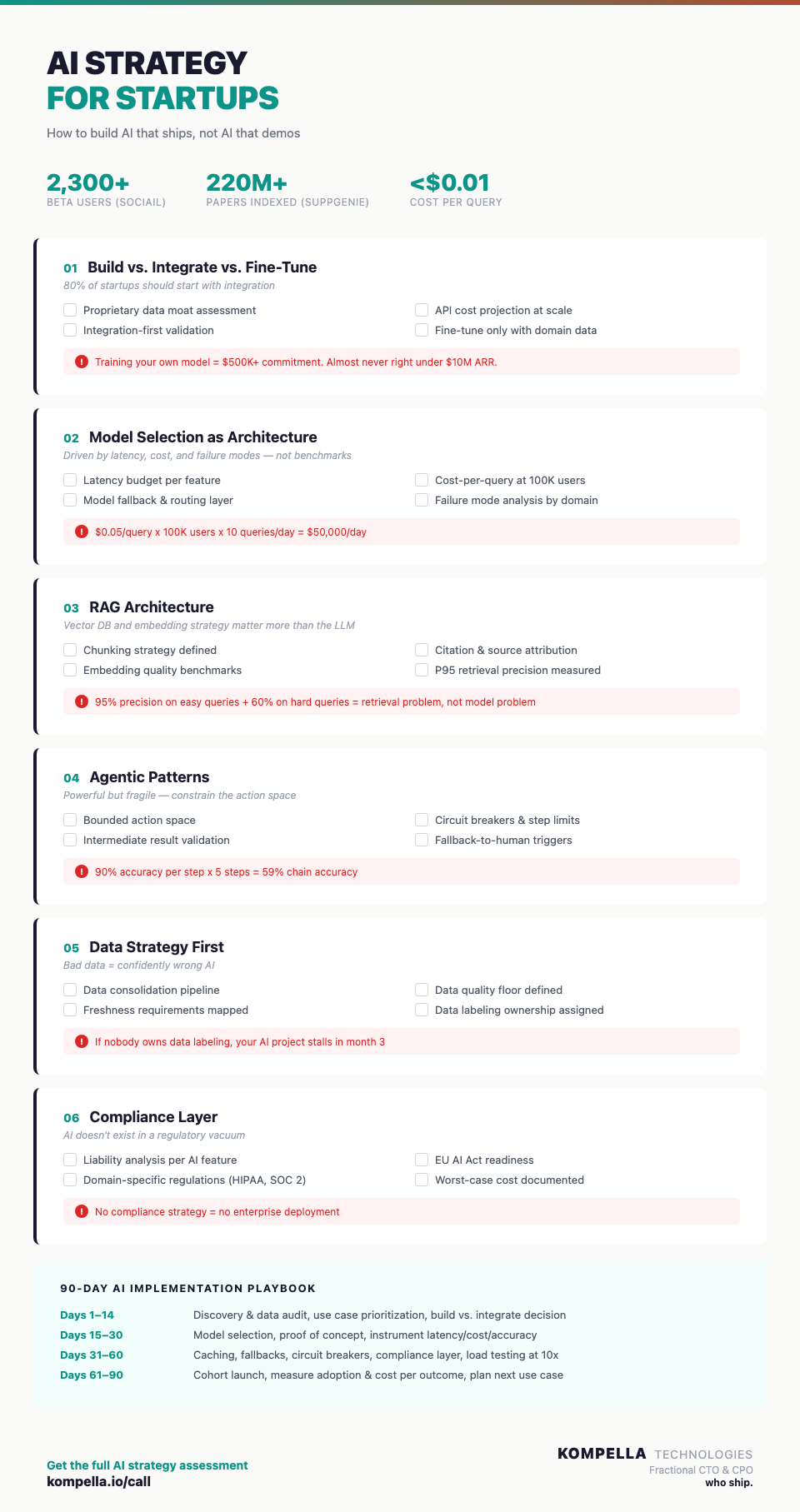
1. Build vs. Integrate vs. Fine-Tune
This is the first fork in the road, and most startups choose wrong.
Build from scratch when you have proprietary training data that creates a genuine moat — not when you want to avoid API costs. Training your own model is a $500K+ commitment in compute, data engineering, and ML ops. Unless you're the product (like a medical imaging company), this is almost never the right call for a startup under $10M ARR.
Integrate existing models (GPT-4, Claude, Gemini) when AI augments your core product but isn't the product itself. This is where 80% of startups should start. With Sociail, we integrated GPT-4 as the language layer while building proprietary orchestration on top — prompt routing, caching, and model fallbacks that kept costs under $0.01 per query.
Fine-tune when you've validated the use case with integration, have domain-specific data, and need performance that general models can't deliver. SuppGenie uses LLaMA embeddings fine-tuned on supplement research literature because general embeddings couldn't distinguish between "clinically validated" and "preliminary in-vitro" studies — a distinction that matters enormously to supplement professionals.
The decision matrix is simple: start with integration, prove the value, then move down the stack only when the data justifies it.
2. Model Selection Is an Architecture Decision, Not a Vendor Decision
Most startups pick a model the way they pick a SaaS tool — read some benchmarks, go with the leader. This is a mistake.
Model selection should be driven by your latency requirements, cost envelope, and failure modes:
Latency budget. A chatbot can tolerate 2–3 seconds. An inline code suggestion needs sub-500ms. A real-time collaboration feature (like Sociail's meeting summarizer) needs responses before the user context-switches. We built Sociail's prompt-routing layer to hit sub-500ms by routing simple queries to faster models and reserving GPT-4 for complex reasoning.
Cost per query at scale. A feature that costs $0.05 per query sounds fine when you have 100 users. At 100,000 users making 10 queries per day, that's $50,000/day. Sociail's caching and model fallback system reduced per-query costs to under $0.01 — a 5x reduction that made the AI layer commercially viable at scale.
Failure modes. When GPT-4 hallucinates in a workplace chat, someone corrects it. When an AI research engine hallucinates a clinical study citation, a supplement company might make a regulatory submission based on a paper that doesn't exist. SuppGenie's architecture includes citation verification, source linking, and confidence scoring specifically because the cost of hallucination in that domain is regulatory risk.
Your model architecture should reflect your domain's tolerance for error, not just your benchmark scores.
3. The RAG Decision: When You Need It and When You Don't
Retrieval-Augmented Generation has become the default architecture for any AI feature that touches proprietary data. But RAG adds complexity, latency, and cost — and many startups implement it poorly.
You need RAG when:
- Your users ask questions about data that changes frequently (product docs, research papers, internal knowledge bases)
- The domain requires citations or source attribution
- General model knowledge is insufficient or outdated for your use case
- The task is generation, not retrieval (copywriting, code generation, summarization of provided text)
- Your data fits within the model's context window and doesn't change often
- You can solve the problem with fine-tuning instead
The metric that matters: retrieval precision at your P95 query complexity. If your RAG system returns relevant results 95% of the time on easy queries but only 60% on the queries that actually matter, you have a retrieval problem, not a model problem.
4. Agentic Patterns: Powerful but Fragile
AI agents — systems where the model decides what tools to call, in what order, and how to chain results — are the most exciting and most dangerous pattern in production AI.
We built agentic patterns into Sociail using LangChain and ReAct-style prompting: a summarizer agent, a scheduler agent, and a GitHub issue auto-creation agent. Here's what we learned:
Agents work when the action space is bounded. Sociail's GitHub agent can create issues, add labels, and assign them. It can't delete repositories or modify CI pipelines. Constraining what agents can do is more important than making them smarter.
Multi-turn error compounds. If each step in an agent chain has 90% accuracy, a 5-step chain has 59% accuracy. Our hybrid scoring system in Sociail's RAG pipeline reduced multi-turn error by 80% by validating intermediate results before passing them to the next step.
Agents need circuit breakers. When the model gets confused, agents can enter infinite loops or take increasingly bizarre actions. We built hard limits on step counts, token budgets, and fallback-to-human patterns that trigger when confidence drops below thresholds.
The rule: use agents for workflows with 3–5 deterministic steps. Use traditional software for everything else.
The mirror-image decision — should my product be callable by other people's agents? — is increasingly answering itself for any startup with a public surface. We unpack that shift, and the four work streams it creates, in Agents Are the New Mobile.
5. Data Strategy Before AI Strategy
The most common failure mode we see isn't bad models or bad prompts — it's bad data.
Startups that try to bolt AI onto messy, unstructured, poorly-labeled data end up with AI that's confidently wrong. Before writing a single prompt, answer these questions:
- Where does your training/context data live? If it's scattered across Google Docs, Notion, Slack, and a PostgreSQL database, your first project is a data consolidation pipeline, not an AI feature.
- How fresh does the data need to be? SuppGenie ingests from PubMed, PMC, OpenAlex, and ClinicalTrials.gov in real-time because supplement research moves fast. If your data changes weekly, a nightly batch job is fine. If it changes hourly, you need streaming ingestion.
- What's your data quality floor? Garbage in, garbage out applies 10x to AI. SuppGenie's AI study ranking only works because every paper is tagged with supplement-specific metadata. Without that tagging layer, the embeddings would treat a randomized controlled trial and a blog post as equivalent.
- Who owns data labeling? If the answer is "nobody," your AI project will stall in month 3.
6. The Compliance Layer Most Startups Skip
AI doesn't exist in a regulatory vacuum, and the compliance landscape is changing fast.
If you're in healthcare, AI touches HIPAA, FDA SaMD pathways, and clinical validation requirements. If you're handling financial data, SOC 2 and data residency rules apply. Even in "unregulated" spaces, the EU AI Act and emerging US state regulations are creating new obligations.
SuppGenie's Compliance Wizard automates FDA GRAS and EFSA Novel Foods flagging because supplement companies face real regulatory risk if they make claims based on insufficient evidence. This wasn't a nice-to-have feature — it was the reason enterprise customers chose SuppGenie over building their own research workflow.
The compliance question to ask before every AI feature: If this model is wrong, who bears the liability, and what's the worst-case cost?
How Do You Implement AI in 90 Days?
Based on our work across multiple AI-native products, here's how we recommend startups approach AI:
Days 1–14: Discovery & Data Audit Map your data landscape. Identify the 2–3 highest-value AI use cases. Assess data quality, freshness, and accessibility. Decide build vs. integrate vs. fine-tune for each.
Days 15–30: Architecture & Proof of Concept Select models based on latency, cost, and failure mode analysis — not benchmarks. Build a working proof of concept for your #1 use case. Instrument everything: latency, cost per query, accuracy, user satisfaction.
Days 31–60: Production Hardening Add caching, fallbacks, and circuit breakers. Implement monitoring and alerting for model performance drift. Build the compliance layer your domain requires. Load test at 10x your current user base.
Days 61–90: Ship, Measure, Iterate Launch to a cohort (not everyone). Track the metrics that matter: adoption rate, task completion, cost per successful outcome. Identify the next use case based on data, not excitement.
What Are Red Flags in Your AI Approach?
If any of these sound familiar, your AI strategy needs a reset:
"We're using AI" but can't articulate the specific user problem it solves. AI is a tool, not a strategy. If the primary motivation is "competitors are doing it" or "investors expect it," you're building a feature that will ship late and get ignored.
Your AI costs are growing faster than your revenue. This usually means no caching strategy, no model tiering, and no cost-per-query monitoring. Sociail's layered approach — cache first, small model second, GPT-4 only when needed — kept costs viable at 2,300+ users.
One engineer "owns" AI and no one else understands it. AI features need the same code review, testing, and documentation rigor as any production system. If your AI is a black box maintained by one person, it's a liability, not an asset.
You fine-tuned before validating with off-the-shelf models. Fine-tuning is expensive and creates maintenance burden. If you haven't proven the use case works with GPT-4 + good prompts first, you're optimizing prematurely.
No evaluation framework. If you can't measure whether your AI is getting better or worse over time, you're flying blind. Every AI feature needs automated evals that run on every deployment.
How Does AI Strategy Affect Fundraising?
Investors in 2026 have seen enough AI demos. What Series A investors actually evaluate in technical due diligence:
- Unit economics of AI features. Cost per query, cost per successful outcome, gross margin impact.
- Defensibility. Is your AI moat in the model, the data, or the workflow? (Hint: data and workflow moats are 10x more durable than model moats.)
- Production maturity. Monitoring, fallbacks, evaluation frameworks, incident response for AI failures.
- Scalability. What happens to your architecture and costs at 10x users? 100x?
When to Bring In a Fractional CTO for AI
Not every startup needs a full-time AI leader, but every startup building AI features needs someone who's shipped AI to production before. The difference between a prototype and a production AI system is the same as the difference between a demo and a company.
A fractional CTO with AI experience can compress the learning curve from 12 months to 90 days — not by writing code, but by making the six decisions above correctly the first time. The cost of getting model selection, RAG architecture, or compliance strategy wrong isn't a delayed feature. It's $200K in wasted engineering time and a product that can't scale.
If your AI initiative has stalled, your costs are spiraling, or you're preparing for due diligence and your AI architecture isn't investor-ready — let's talk.
Related reading from Kompella Technologies:
- AI That Learns on the Job: A 2027 Roadmap — planning your product roadmap for continual learning, before it arrives
