Most technical due diligence fails before it starts. Not because the technology is bad, but because the people running the assessment don't know what actually matters.
I've sat on both sides of this table — as the fractional CTO preparing a startup for investor scrutiny, and as the technical advisor evaluating targets for PE firms and strategic acquirers. Across 75+ product assessments, I've seen the same pattern: investors fixate on surface-level metrics (test coverage percentages, deployment frequency) while missing the structural issues that actually blow up post-close.
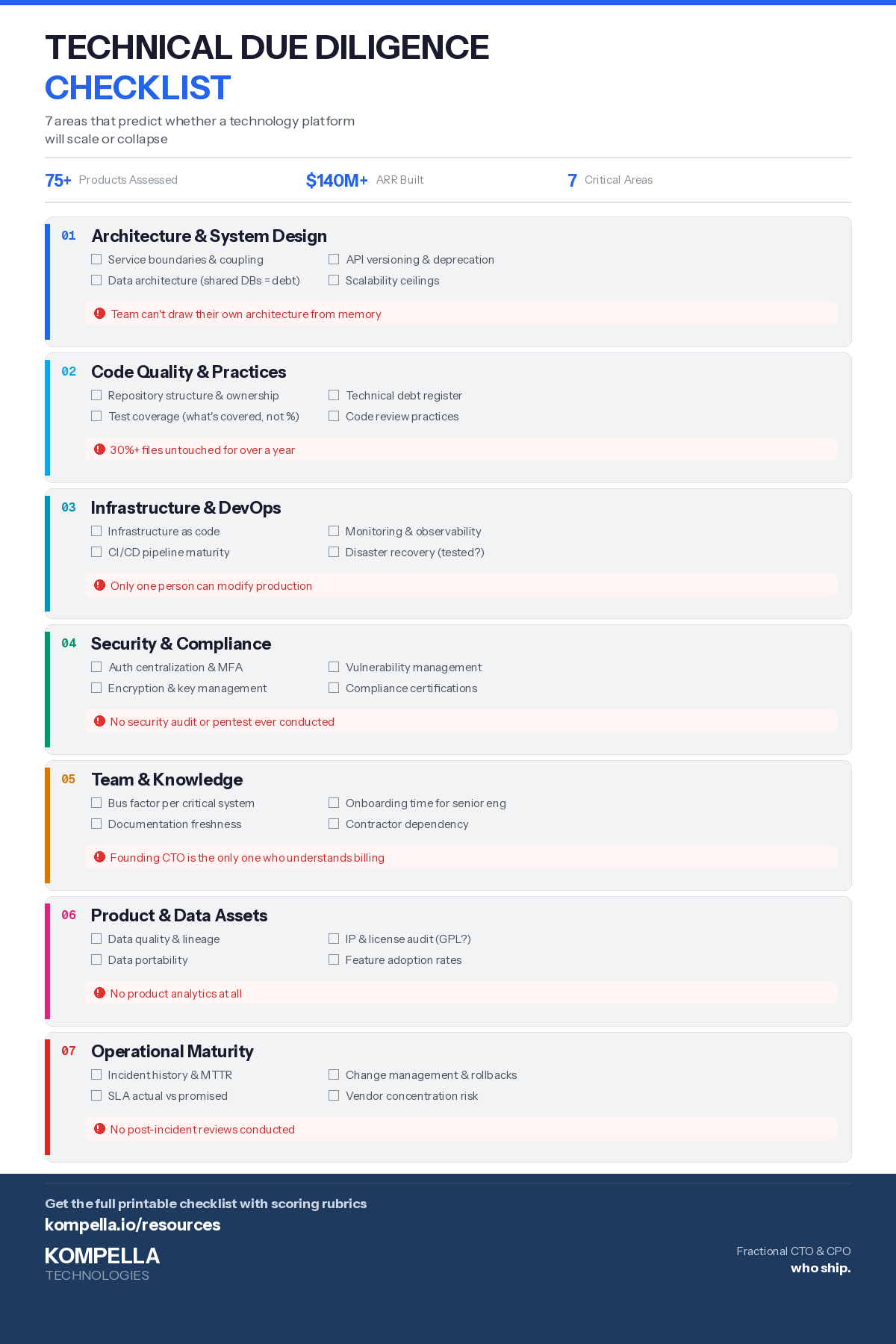
This checklist is what I use in the field. It's organized by the seven areas that predict whether a technology platform will scale or collapse under new ownership. If you want the condensed version you can print and bring into a diligence room, grab the PDF checklist from our resources page.
1. Architecture and System Design
Architecture tells you more about a company's technical maturity than any other signal. A well-architected system built by a small team is worth more than a messy system built by fifty engineers.
What to evaluate:
- Service boundaries and coupling. Are services decomposed along business domains, or is it a distributed monolith where every change requires coordinating three teams? Ask for a system diagram and then ask the team to explain the last cross-service change they shipped. If it took more than a week of coordination, coupling is too tight.
- Data architecture. Where does the source of truth live for each business entity? How many databases exist, and do services share databases directly? Shared databases between services are the single most expensive architectural debt to unwind post-acquisition.
- API design and versioning. Are APIs versioned? Is there a deprecation policy? Companies that break API contracts without versioning will break integrations with your existing portfolio companies.
- Scalability ceilings. Every system has a bottleneck. Ask the team where theirs is. If they can't answer immediately, they haven't hit it yet — which means they also haven't planned for it. Look for single-threaded processes, unsharded databases, and synchronous workflows that should be async.
- Technology choices and currency. Being on the latest framework doesn't matter. Being on an unsupported one does. Flag anything end-of-life within 18 months (Node.js versions, Python 2 remnants, outdated cloud SDKs). Each one represents forced migration cost.
2. Code Quality and Engineering Practices
Code quality isn't about style guides — it's about whether the next team can maintain and extend this codebase without the current team's tribal knowledge.
What to evaluate:
- Repository structure. Is the codebase in one monorepo or scattered across dozens of repositories with unclear ownership? Either can work, but the boundaries need to be intentional. Count the repos with no commits in 6+ months — that's your abandoned code surface area.
- Test coverage — but not the way you think. The coverage percentage matters less than what's covered. I've seen 80% coverage that tests nothing meaningful and 40% coverage that catches every critical business rule. Ask to see the tests for the three most important business workflows. If those aren't covered, the number is decorative.
- Technical debt register. Does the team track their debt, or does it just accumulate? A team that maintains a prioritized tech debt backlog is operationally mature. A team that says "we don't have much tech debt" is either lying or unaware — both are concerning.
- Code review practices. Are PRs reviewed before merge? What's the average review turnaround? Look at the last 20 merged PRs. If any went in without review, or if one person approved all of them, the review process is performative.
- Dependency management. How many third-party dependencies exist, and when were they last updated? Run a vulnerability scan. Outdated dependencies with known CVEs are a concrete, quantifiable risk you can present to the investment committee.
3. Infrastructure and DevOps
Infrastructure decisions made two years ago determine your operational costs for the next two years. This section separates companies that have outgrown their infrastructure from those that scaled it intentionally.
What to evaluate:
- Infrastructure as code. Can the entire production environment be rebuilt from a repository? If the answer involves someone SSHing into servers and running manual commands, you're buying a system that depends on that someone being available at 3 AM forever.
- CI/CD pipeline maturity. How long does it take to go from merged code to production? The number itself matters less than the trend. A team that deploys daily has caught most of their process issues. A team that deploys monthly is batch-loading risk.
- Monitoring and observability. Ask to see the dashboard the on-call engineer uses. If there isn't one, incidents are detected by customers, not engineers. Check whether alerts are actionable (specific service, specific metric) or noise (CPU above 80% on a bursty workload).
- Disaster recovery. When was the last time backups were actually restored — not just created, restored? Ask for the RTO and RPO numbers, then ask when they were last validated. Most companies have numbers on paper that have never been tested.
- Cloud spend efficiency. Request the last 6 months of cloud bills. Look for the ratio of spend to revenue. Startups burning more than 15-20% of ARR on infrastructure either have a scaling problem or an optimization opportunity worth quantifying.
4. Security and Compliance
Security findings kill deals. Not because every vulnerability is critical, but because they signal how seriously the organization takes operational risk.
What to evaluate:
- Authentication and authorization. Is auth centralized or implemented differently across services? Are passwords hashed with modern algorithms (bcrypt, argon2) or something deprecated? Is MFA available, and is it enforced for admin access?
- Data encryption. At rest and in transit are table stakes. The real question is key management — who has access to encryption keys, how are they rotated, and is the rotation automated? Manual key rotation means it doesn't happen on schedule.
- Vulnerability management. When was the last penetration test? Is there a process for triaging and patching CVEs? Request the timeline from the last critical vulnerability discovery to deployed fix. Anything over 72 hours for a critical CVE is a process problem.
- Compliance posture. SOC 2, HIPAA, GDPR, PCI — which are relevant and which are in place? If the company claims compliance but can't produce the audit report, they're compliant in spirit only. Check expiration dates on certifications.
- Access control and offboarding. How quickly do departing employees lose access? Check whether any former employee accounts are still active. In the healthcare products I've worked with — like Aesthetic Record serving 4,000+ US clinics — access control isn't just best practice, it's a regulatory requirement with real enforcement consequences.
5. Team and Knowledge Distribution
You're not just acquiring code — you're acquiring the team that understands it. The biggest post-acquisition risk isn't technology failure, it's knowledge walking out the door.
What to evaluate:
- Bus factor analysis. For each critical system, how many people can make changes without asking someone else? If the answer is one for any system that generates revenue, that's a retention risk you need to price into the deal.
- Documentation culture. Not the existence of documentation — the freshness of it. Check the last-modified dates on architectural decision records, runbooks, and onboarding guides. Documentation older than 12 months is often more dangerous than no documentation because it's confidently wrong.
- Onboarding time. Ask the last person hired how long it took to make their first meaningful contribution. This number tells you the actual complexity of the system, regardless of what the architecture diagram suggests. More than 4 weeks for a senior engineer means the codebase has significant implicit knowledge.
- Retention patterns. Look at engineering turnover for the last 24 months. High turnover in specific teams signals management or technical problems in those areas. Look at who left and what they owned.
- Contractor dependency. What percentage of the codebase was built by contractors who are no longer engaged? Contractor-built code without knowledge transfer is effectively undocumented.
6. Product and Data Assets
The technology is the means, but the data is often the actual asset being acquired. Make sure you're evaluating what's truly valuable.
What to evaluate:
- Data quality and lineage. Where does each data source originate, how is it transformed, and where does it end up? Can the team trace a customer record from ingestion to the reporting dashboard? Data without lineage is data you can't trust.
- Data portability. If you need to migrate this data to a different platform, how painful is that? Proprietary formats, vendor-locked storage, and undocumented schemas all increase migration cost. Ask the team to estimate a full data export timeline.
- Analytics capabilities. Is there a data warehouse or are people running queries against production? Querying production directly means analytics are competing with user-facing workloads — and it means the analytics infrastructure hasn't been invested in.
- IP and licensing. Are all third-party libraries properly licensed for commercial use? Has anyone audited for GPL contamination in a proprietary codebase? A single GPL dependency in a closed-source product creates a legal exposure that's painful to unwind.
- Feature adoption. What percentage of shipped features are actually used by customers? Request product analytics showing feature usage distribution. If 40% of the codebase serves features that less than 5% of users touch, you're maintaining (and acquiring) dead weight.
7. Operational Maturity
Operational maturity predicts how much investment you'll need post-close just to keep the lights on, before you can start building new value.
What to evaluate:
- Incident history. Request the last 12 months of production incidents. Look at frequency, severity, mean time to detect (MTTD), and mean time to resolve (MTTR). A company that averages under 4 hours MTTR has mature incident response. Over 24 hours means every outage becomes a fire drill.
- SLA performance. If the company has customer-facing SLAs, what's the actual uptime over the last year? Compare the promised number to the real number. A gap between the two means either the SLAs are aspirational or monitoring isn't catching downtime.
- Change management. How are database migrations handled? Is there a rollback plan for every deployment? Ask about the last failed deployment and how it was handled. The answer tells you more than any process document.
- Capacity planning. Does the team proactively plan for growth, or do they scale reactively when things break? Ask about the last time they scaled infrastructure. If it was in response to an outage, capacity planning is reactive.
- Vendor dependencies. Map every third-party service the product depends on. For each one, ask what happens if that vendor goes down or raises prices 10x. Companies with single-vendor dependencies for critical functionality have concentration risk.
How Do You Conduct Technical Due Diligence?
This isn't meant to be a pass/fail scorecard. Every company has issues — the question is whether those issues are priced into the deal and whether they're fixable with known investment.
When I run technical due diligence for clients, I categorize findings into three buckets: deal-breakers (structural issues that fundamentally change the valuation thesis), price adjustments (quantifiable risks that should be reflected in the offer), and post-close roadmap items (improvements to plan for in the first 90 days).
If you want the printable version of this checklist with scoring rubrics for each section, download the Technical Due Diligence Checklist PDF from our resources page.
For founders preparing for diligence — whether for a funding round, acquisition, or strategic partnership — the best time to run this assessment is before the other side does. A fractional CTO can run this evaluation in 2-3 weeks and help you fix the critical findings before they show up in someone else's diligence report.
Book a strategy call if you want to discuss your specific situation.
Frequently Asked Questions
How long does technical due diligence typically take?
For a Series A-stage startup, a thorough technical assessment takes 2-3 weeks. Enterprise acquisitions with multiple products and larger engineering teams can take 4-8 weeks. The timeline depends on how organized the target company's documentation is and how accessible the engineering team is for interviews.
Who should conduct technical due diligence?
Someone with hands-on engineering leadership experience who has also operated at the business level. Pure engineers miss commercial implications. Pure business people miss technical risks. A fractional CTO with experience across multiple companies and industries is often the most cost-effective option because they've seen the patterns before.
What are the most common deal-breakers found during tech due diligence?
In my experience across 75+ assessments, the top three are: single points of failure in critical systems (especially when tied to one person), undisclosed security vulnerabilities with regulatory implications, and massive hidden technical debt that would require 6-12 months of remediation before new features could be built.
Should founders prepare for technical due diligence before a funding round?
Absolutely. Investors at Series A and beyond increasingly conduct technical assessments, and findings directly impact valuation. Running a self-assessment 2-3 months before fundraising gives you time to fix critical issues and present a clean report that builds investor confidence.
How is technical due diligence different from a code audit?
A code audit examines the codebase in isolation. Technical due diligence evaluates the entire technology operation — architecture, infrastructure, security, team, processes, and data assets — in the context of a business transaction. The output isn't a list of code issues; it's a risk assessment that informs investment decisions.
What does technical due diligence cost?
Costs range from $15,000 to $75,000 depending on scope and complexity. For startups preparing for fundraising, a lighter pre-diligence assessment through a fractional CTO engagement can be done within an existing retainer ($8,000-$25,000/month) as part of broader technical leadership.
